
Azure Databricks, Azure ADLS Gen2, and Daturic
- Typical Databricks Governance Controls
- Data Lake Governance Controls
- Databricks Control Complexity as it Scales
- Databricks Controls Simplified with Daturic
Many companies have embarked on multi-year initiatives to make organizational data available to toolsets such as Azure Databricks in order to support business decision processes. Databricks works by providing a dynamic compute environment that can be used to connect to existing data storage services, such as Azure Data Lake Gen 2 (ADLS Gen2). Even though business data should be accessible for these purposes, there are still governance controls that need to apply to control who can use what data and in what context. When using Azure Databricks in your environment, there are a couple of different ways you can secure access to approved data. The following diagram shows the overall picture.
Typical Databricks Governance Controls
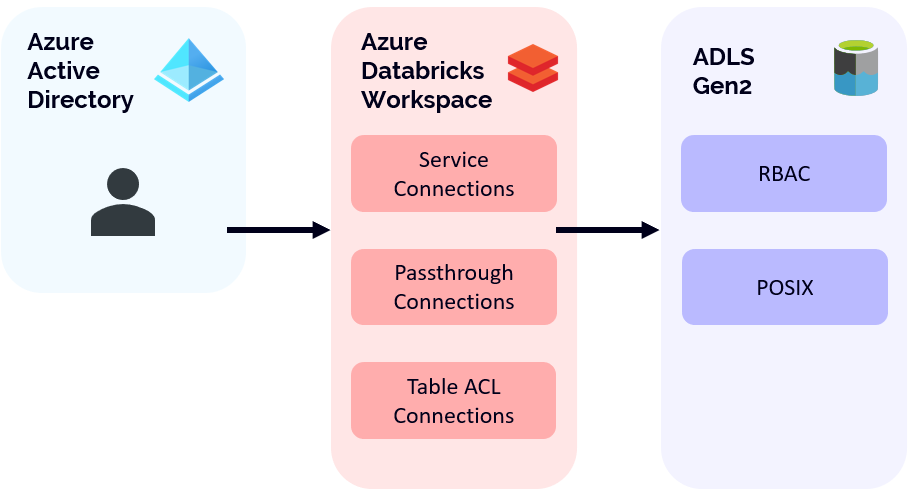
Effectively, Azure databricks workspaces can be created that provide users access to data. These workspaces are, from an identity standpoint, tied into Azure Active Directory, which means that only users within your Azure Active Directory Tenant can log in. Once users have access to a workspace, they can make use of a couple of different authorization methods to gain access to data.
In the first case, let’s examine service connections. In this use case, Azure Databricks (either at the session or cluster level) is configured with a service principal that is used to access data. Users with direct access to run notebooks on a cluster do so within the security context of the service connection itself. This means that whatever data access has been granted to the service connection, the user also has.
Passthrough connections are a special type of cluster configuration within Azure Databricks. In this access method, the user context is passed when making calls to access data. This allows data access administrators to configure appropriate permissions by user within the workspace, rather than by service principal.
The last access method is via Table ACLs. Table ACLs effectively use either service connections or passthrough connections depending on how the tables are being accessed. Typically used with the Azure Databricks SQL Endpoints, users can query tables and have permissions enforced within the Databricks workspace. These permissions are above and beyond the permissions that may already be applied via the service connection (or passthrough connection) talked about above. One interesting advantage is that Databricks Tables can also be used to enforce more granular permissions, such as column or row level security. The trade-off here is that Table ACLs only work on relational data, stored in some sort of table format within ADLS Gen 2, such as Databricks Delta.
Data Lake Governance Controls
In all the cases above, the Databricks workspace itself needs to be granted access to target data lakes. From an Azure perspective, there are two options. The first is Azure Role Based Access Control (Azure RBAC). In this method, broad permissions are granted to either the entire storage account, or a container within that storage account. You cannot enforce Azure RBAC at the folder or file level. The second option is to make use of POSIX controls within the target data lake. This method is the most granular, allowing you to provide fine grained access to files and folders that reside on the data lake.
While the above discussion on access control seems to work well when you are in a one-to-one situation (between Azure Databricks workspace and ADLS Gen2) you can get into more complex access permission as you scale the solution. For example, because of how permissions within an Azure databricks workspace function, many organizations are moving to an “explore” or “studio” type deployment model whereby workspaces are created, fit for purpose, for certain exploratory or project or ML training type scenarios. These are in addition to standard workspaces that have been provisioned for data engineering activities.
Another scenario that adds complexity is when organizations want to share data between various workspaces. In some project based workspace scenarios, data may need to be read from one data lake (let’s say production) and then outputs written to another data lake (a project specific one) for review to support the development process.
Lastly, organizations that adopt a data mesh type pattern may actually have various business units with their own data lakes. Conceptually, most Azure Databricks environments look something like this:
Databricks Control Complexity as it Scales
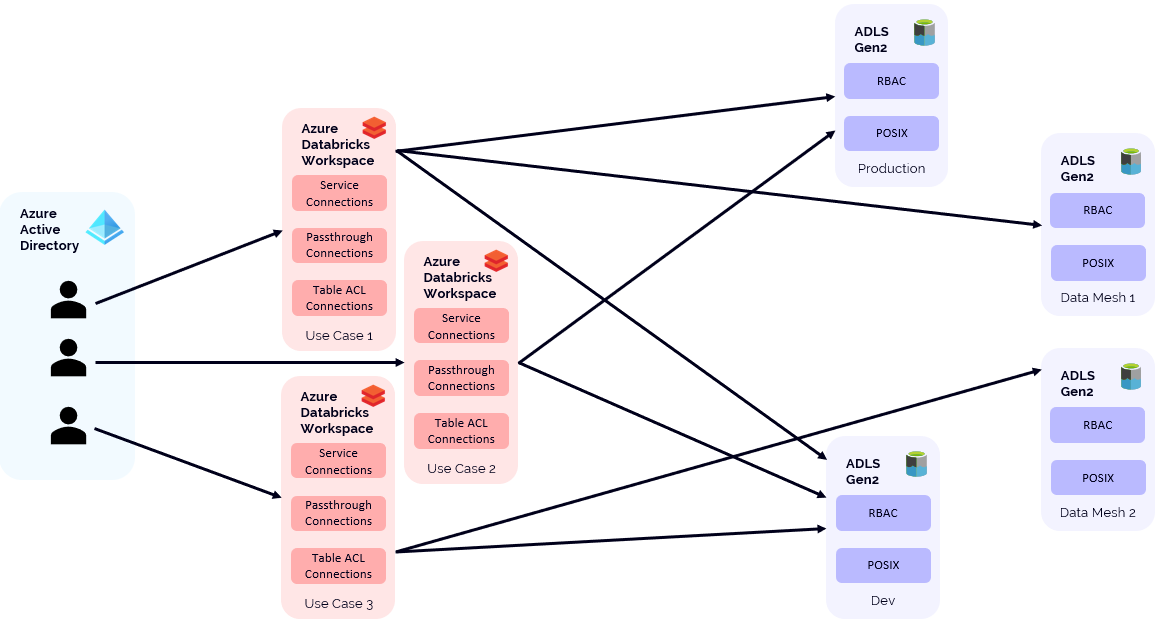
Now we can see that at scale, ensuring that each workspace has appropriate access to target data sources (and destinations) can become quite the problem to solve. This is the value that Daturic provides. With Daturic, the data access is managed through easy to understand policies with tags providing context allowing your data landscape to look like this:
Databricks Controls Simplified with Daturic
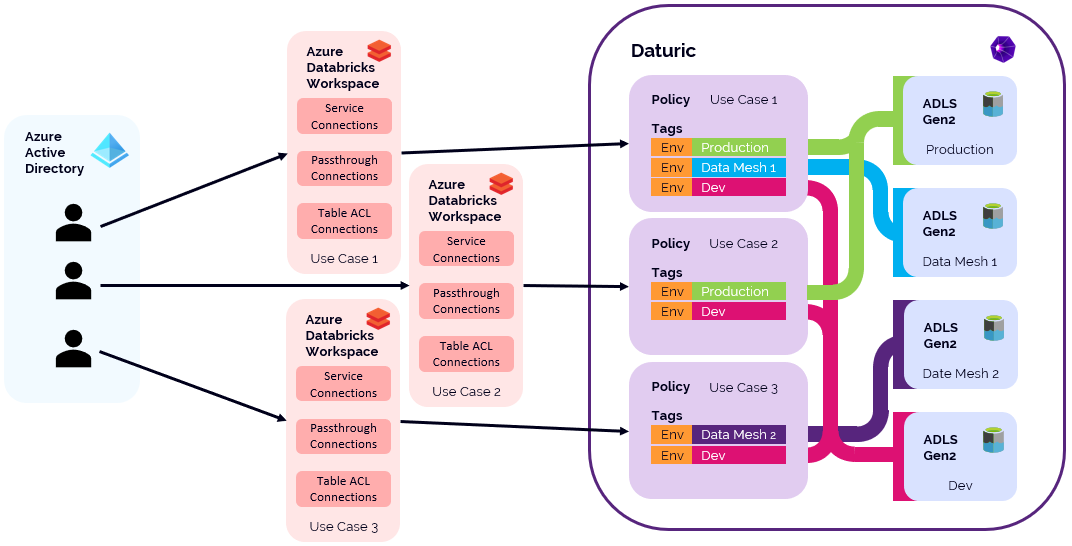
Daturic provides a unified tagging and policy layer that can be controlled by data governance and can be applied to all data lakes managed by Daturic. Because Daturic crystalizes it’s policies on the data lake (using POSIX permissions) and within Azure Active Directory (using groups) it reduces the administrative overhead of providing the correct level of access to existing data across your entire Azure Databricks environment. Further, using Daturic doesn’t limit using existing capabilities (such as Table ACLs) within the Databricks workspace to further refine access controls.
Enhance your Databricks environment with Daturic providing greater visibility and simplifying the access structure, helping your organization to rapidly realize the value of your data.